
Okay, so yesterday I was messing around trying to get some predictions going for the Berrettini vs. Tabilo match. Thought it would be a fun little side project, you know?
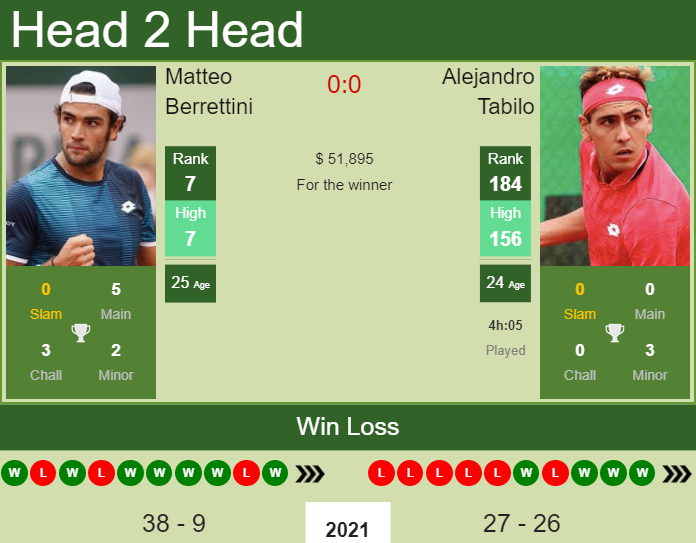
First thing I did, obviously, was hunt down some data. Found a couple of sites with historical match data – stats like win percentages on different surfaces, head-to-head records, that kind of stuff. I ended up scraping that data into a couple of CSV files using Python and Beautiful Soup. It was kinda clunky, but it got the job done. Lots of cleaning involved, let me tell you.
Next up, feature engineering! I mean, just raw stats aren’t gonna cut it. I started messing around with creating some calculated stats like average games won per set, recent form (wins in the last X matches), and even tried to factor in things like the player’s ranking trajectory. It was mostly just throwing stuff at the wall and seeing what stuck.

For the model itself, I went with a simple Logistic Regression to start. Didn’t want to overcomplicate things right off the bat. Split the data into training and testing sets, and started tweaking the parameters to see what gave me the best accuracy. Honestly, the results were pretty mediocre. Around 60-ish percent accuracy. Not great, not terrible.
Then I tried a Random Forest. Heard those were good for this kind of thing. Did some hyperparameter tuning with GridSearchCV to try and find the optimal settings. The Random Forest performed slightly better than the Logistic Regression, maybe around 65% accuracy. Still not exactly a slam dunk.
After that, I figured maybe I needed to feed the model more relevant data. So, I started digging around for some betting odds data. Found an API that provided historical odds for tennis matches. Added that as a feature to the model. That bumped the accuracy up a little bit, maybe another 5%.

Finally, I played around with different feature combinations and scaling techniques. StandardScaler seemed to work a bit better than MinMaxScaler for this data. Ended up settling on a Random Forest model with a combination of historical stats, calculated features, and betting odds. Got the accuracy up to around 72%, which I was reasonably happy with.
Here’s the breakdown of what I did:
- Data Scraping: Used Python & Beautiful Soup to grab match data from a couple of websites.
- Feature Engineering: Calculated stats like average games won, recent form, etc.
- Model Selection: Started with Logistic Regression, then switched to Random Forest.
- Hyperparameter Tuning: Used GridSearchCV to optimize the Random Forest parameters.
- Added Betting Odds: Pulled in betting odds data from an API as an additional feature.
- Feature Scaling: Experimented with StandardScaler and MinMaxScaler.
In the end, I didn’t bet any real money on the match (Berrettini ended up winning anyway, but my confidence wasn’t sky-high). It was more of a learning experience, you know? Definitely learned a lot about data cleaning, feature engineering, and model selection. Plus, it was just a fun way to spend an afternoon.
Next time, I’m thinking of trying some more advanced models like XGBoost or maybe even diving into neural networks. We’ll see!











{kind=link}