
Okay, so today I’m gonna walk you through how I tackled setting up a depth chart using UH (University of Houston) data. It wasn’t exactly smooth sailing, but hey, that’s why we document these things, right?

First things first, I grabbed the UH football roster data. I literally just scraped it off their website. It was a bit of a mess, to be honest. Different formats, inconsistent naming conventions… the works. I initially thought about using some fancy web scraping library, but in the end, a simple “copy-paste into a CSV” job got me started quicker. Don’t over-engineer it, folks!
Next, I imported the CSV into a Pandas DataFrame. If you’re not using Pandas for data manipulation, you’re missing out. Seriously. I then spent a good chunk of time cleaning the data. Think renaming columns to be more descriptive, fixing typos in player names (you’d be surprised how often that happens), and standardizing positions. This was honestly the most tedious part, but crucial. Garbage in, garbage out, you know?

Then came the fun part: actually building the depth chart. I decided to represent it as a dictionary. The keys were the positions (e.g., QB, RB, WR), and the values were lists of players at that position, ordered by their depth. So, the first player in the list would be the starter, the second would be the backup, and so on. Iterating over the cleaned data, I assigned each player to their corresponding position list. The biggest challenge here was figuring out how to determine the order. UH doesn’t exactly publish a definitive depth chart, so I had to rely on things like game participation stats (who played the most), news articles (who’s getting the hype), and a healthy dose of educated guesses. It’s not perfect, but it’s a start.
After that, I wrote a simple function to display the depth chart in a readable format. Nothing fancy, just a plain text output. Something like:
- QB: [Player A, Player B, Player C]
- RB: [Player X, Player Y, Player Z]
- WR: [Player 1, Player 2, Player 3]
I even added some basic error handling to catch any positions with no players assigned (empty lists). Gotta be robust, right?
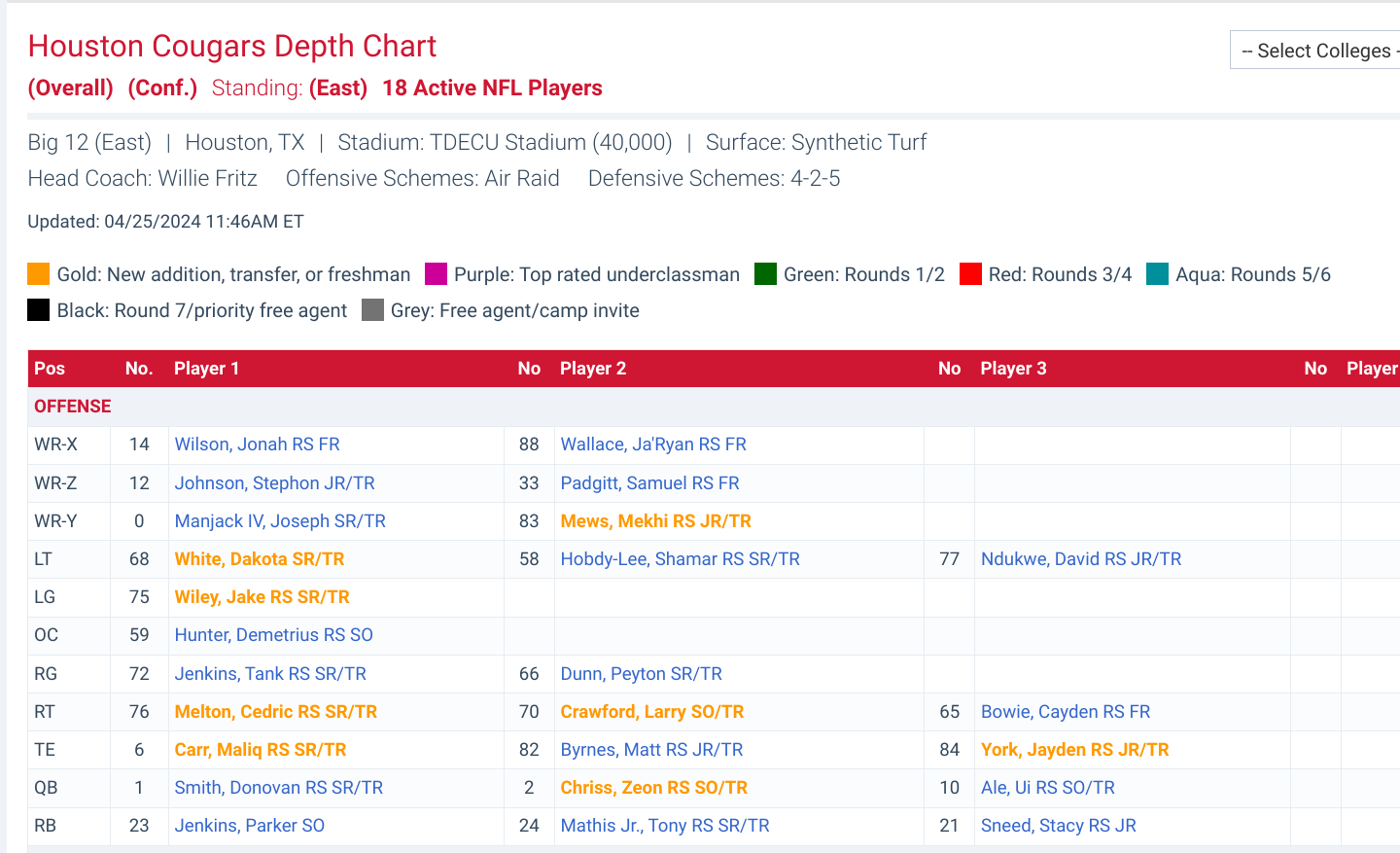
Finally, I saved the depth chart to a JSON file. This way, I can easily load it up later and make adjustments as the season progresses and more information becomes available.
Learnings? Data cleaning is always more time-consuming than you think. Also, don’t be afraid to use simple tools to get the job done. And finally, building a depth chart without official sources is more art than science. It’s a living document that needs to be constantly updated and refined. But hey, that’s part of the fun!











{kind=link}